查询在一张表不在另外一张表的记录
作者:admin 发布于:2017-4-27 15:49 Thursday
参考文献
http://hi.baidu.com/zdfgng/blog/item/dd5f88359a1cd0260b55a9ce.html
题目
假如要查询在a表中存在,但是在b表中不存在的记录,应该如何查询。为了便于说明,我们假设a表和b表都只有一个字段id,a表中的记录为{1,2,3,4,5},b表中的记录为{2,4},那么我们需要通过一个sql查询得到{1,3,5}这样的结果集。
一般解法(效率低)
看到这个题目,我们首先想到的可能就是not in这样的关键字,具体的查询语句如下:
select ta.* from ta where ta.id not in(select tb.id from tb)
上述查询语句的查询结果集确实是{1,3,5},用navicat执行上述语句,得到如下图所示结果:
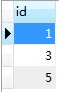
效率分析
但是仔细分析我们可以发现,如果b表很长,那么执行上述的查询语句,需要用a表中的字段去匹配b表中的每一个字段,相当于是a表的每一个字段都要遍历一次b表,效率非常低下。(只要a中的字段不在b表中那么肯定要遍历完b表,如果a表中的字段在b表中,那么只要遍历到就退出,进行a表中下一个字段的匹配)
使用连接解决
连接查询使我们平时进行sql查询用到最多的操作之一了,相对于上述not in关键字,我们使用连接查询的效率更高。因为我们需要搜索的是a表中的内容,所以使用a表左连接b表,这样b表中会补null,查询语句如下:
select * from ta left join tb on ta.id=tb.id
上述查询语句的查询结果如下:
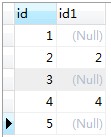
因为a、b两表中字段id相同,所以上述b表中的id字段变成了id1。仔细观察由可以发现,我们需要的结果集{1,3,5}所对应的id1字段都是null。这样我们在上述的查询语句中加入条件即可完成对只在a表中,但不在b表中的结果集的插叙,查询语句如下:
select * from ta left join tb on ta.id=tb.id where tb.id is null
查询结果如下图所示:

但是我们又发现上述查询结果有2列,也就是a表和b表的连接查询结果,但是我们只需要a表中的内容,所以对上述查询稍作修改:
select ta.* from ta left join tb on ta.id=tb.id where tb.id is null
查询结果如下图所示:
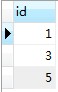
以上就是我们所要求的查询结果。
详解(PS:2012-9-7)
数据准备
 View Code
View Code时隔三个月再来看这道题目,又有新的发现,之前还是只是半知半解,在写完SQL Server Join方式这篇博客以后基本就明白这道题目的核心了,核心是:我应该使用何种联接方式来查询结果。
我们能够写出来的最直观的TSQL语句应该是:
select ta.* from ta where ta.id not in(select tb.id from tb)
然后我们看看这个语句的查询计划:
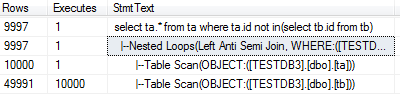
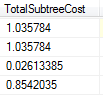
从上图我们可以发现使用了Nested Loops的联接方式,但是我们知道nested loop联接方式的使用场景是:比较适合于两个比较小的结果集做联接,或者至少是Outer table的结果集比较小。而上面的outer table是ta,它是大表,所以可以发现nested loop不适合。注意:虽然上面的查询语句中没有join字段,但是还是使用了join。
假如我们使用left join 来写查询语句的话,sql server会帮我们选择何种联接方式呢?测试如下:
select ta.id from ta left join tb on ta.id=tb.id where tb.id is NULL--Hash Match
上述查询的执行执行计划如下图所示:
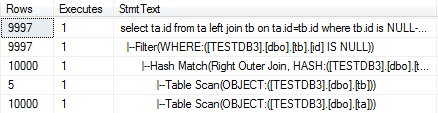
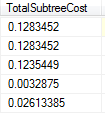
从上图我们可以发现sql server帮我们选择了使用Hash Match。这是因为在上述联接中,ta是大表,ta和tb两表之间数据量差距很大,还有ta和tb都没有索引。从执行计划的TotalSubtreeCost中也可以看出来,使用Hash Match的TotalSubtreeCost=0.12,而是用Nested Loop的TotalSubtreeCost=1.03。可以发现Hash Match性能比Nest Loop好很多。
那么使用Merge Join能,起性能如何?我们可以通过使用sql hint来建议sql server使用特定的联接方式,执行如下TSQL语句:
select ta.id from ta left merge join tb on ta.id=tb.id where tb.id is NULL--Merge Join
其执行计划如下图所示:
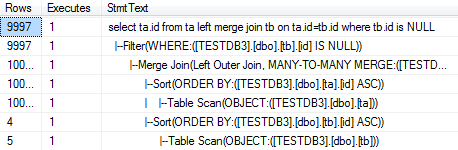
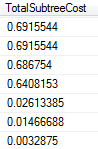
从上图可以看出:
- 因为查询列上都没有索引,所以查询出来的结果不一定是排序的,这样sql server帮我们做了排序操作。
- 在做完排序操作以后进行的是Merge Join操作,整个查询所使用的TotalSubtreeCost=0.69,好于Nested Loop,比Hash Match性能差。
所以我们在回答上面题目的时候,必须说明使用Hash Match,而不只是给出left join的答案,之所以查询结果最有是因为sql server帮我们分析了使用Hash Match性能最优。
所有查询方式:

select ta.* from ta where ta.id not in(select tb.id from tb)select ta.id from ta where ta.id not in(select tb.id from tb)--Nested Loops select ta.id from ta left loop join tb on ta.id=tb.id where tb.id is NULL--Nested Loops select ta.id from ta left merge join tb on ta.id=tb.id where tb.id is NULL--Merge Joinselect ta.id from ta left hash join tb on ta.id=tb.id where tb.id is NULL--Hash Match
出处:http://www.cnblogs.com/xwdreamer/archive/2012/06/01/2530597.html